







第3 章搜索技术
•对于给定的问题,智能系统的行为一般是 找到 能够达到所希望目标的动作序列 ,并 使其所付出的代价最小、性能最好。
•基于给定的问题,问题求解的第一步是目 标的表示。
•搜索就是找到智能系统的动作序列的过程。
求解问题包括:
• 目标表示
• 搜索
• 执行
给定问题就是确定该问题的基本信息:
(1)初始状态集合:定义了问题的初始状态。
(2)操作符集合:把一个问题从一个状态变换 为另一个状态的动作集合。
(3)目标检测函数:用来确定一个状态是不是 目标。
(4)路径费用函数:对每条路径赋予一定费用 的函数。
搜索问题包括:
• 搜索什么(目标)
• 在哪里搜索(搜索空间)
搜索分成:
• 状态空间的生成阶段
• 在该状态空间中对所求问题状态的搜索
搜索可以根据是否使用启发式信息分为
1. 盲目搜索 (Uninformed Search):
盲目搜索算法不使用任何关于问题领域的先验知识来指导搜索过程。 它们以一种系统的方式探索状态空间,直到找到目标状态或搜索空间耗尽。 盲目搜索算法的效率通常较低,尤其是在状态空间很大的情况下。
常见的盲目搜索算法包括:
- 广度优先搜索 (Breadth-First Search, BFS): BFS 按照层级顺序探索状态空间。 它首先探索根节点的所有子节点,然后探索这些子节点的子节点,依次类推。 BFS 保证找到最短路径(如果路径长度用边数衡量),但空间复杂度很高。
- 深度优先搜索 (Depth-First Search, DFS): DFS 沿着一条路径尽可能深入地探索状态空间,直到找到目标状态或到达一条路径的尽头。 然后,它回溯到上一个节点,并探索另一条路径。 DFS 的空间复杂度较低,但可能找不到最短路径,甚至可能陷入无限循环。
- 深度受限搜索 (Depth-Limited Search): 这是对深度优先搜索的改进,它设置了一个最大深度限制,避免无限循环。
- 迭代加深搜索 (Iterative Deepening Depth-First Search, IDDFS): IDDFS 结合了深度优先搜索和深度受限搜索的优点。 它首先进行深度受限搜索,深度限制为 1,然后逐渐增加深度限制,直到找到目标状态。 IDDFS 保证找到最短路径,并且空间复杂度较低。
盲目搜索的优缺点:
优点:
- 简单易懂,实现相对容易。
缺点:
- 效率低,尤其是在状态空间很大的情况下。
- 不保证找到最优解(除了 BFS 在特定条件下)。
- 可能陷入无限循环(DFS)。
2. 启发式搜索 (Heuristic Search):
启发式搜索算法利用关于问题领域的先验知识来指导搜索过程。 它们使用启发式函数来评估状态的“好坏”,并优先探索更有可能导致目标状态的路径。 启发式搜索算法通常比盲目搜索算法效率更高。
常见的启发式搜索算法包括:
- 贪婪最佳优先搜索 (Greedy Best-First Search): 贪婪最佳优先搜索使用启发式函数来选择下一个要探索的状态。 它总是选择启发式函数值最小的状态进行扩展。 贪婪最佳优先搜索简单快速,但并不保证找到最优解。
- A 搜索: * A* 搜索结合了贪婪最佳优先搜索和一致代价搜索的优点。 它使用一个评估函数 f(n) = g(n) + h(n) 来选择下一个要探索的状态,其中 g(n) 是从起始状态到状态 n 的代价,h(n) 是从状态 n 到目标状态的启发式代价估计。 A* 搜索在满足某些条件下保证找到最优解。
启发式搜索的优缺点:
优点:
- 效率高,比盲目搜索算法效率高得多。
- 通常能够找到最优解(A* 搜索在满足条件下)。
缺点:
- 需要设计合适的启发式函数。 启发式函数的设计质量直接影响搜索效率。
- 启发式函数的计算代价可能较高。
搜索策略评价标准
1. 完备性 (Completeness):
完备性是指搜索策略是否保证能够找到解,如果解存在的话。 一个完备的搜索策略会系统地探索整个搜索空间,直到找到解或证明解不存在。
- 完备的例子: 广度优先搜索 (BFS) 和迭代加深搜索 (IDDFS) 在有限状态空间中是完备的。
- 不完备的例子: 深度优先搜索 (DFS) 在无限状态空间中是不完备的,因为它可能陷入无限深度的分支而无法探索其他分支。 一些启发式搜索算法,例如贪婪最佳优先搜索,也可能是不完备的,因为它们可能错过某些包含解的分支。
2. 时间复杂性 (Time Complexity):
时间复杂性衡量搜索算法找到解所需的时间。 它通常用状态空间的大小 (b,分支因子) 和解的深度 (d) 来表示。 时间复杂性通常表示为算法执行步骤的数量,这与实际运行时间成正比。
- 例子: BFS 的时间复杂度是 O(b<sup>d</sup>),因为它需要探索所有深度小于等于 d 的节点。 DFS 的时间复杂度在最坏情况下也是 O(b<sup>d</sup>),但它可能在找到解之前就探索了大量无用的节点。 A* 算法的时间复杂度取决于启发式函数的质量和状态空间的大小,难以给出统一的表示。
3. 空间复杂性 (Space Complexity):
空间复杂性衡量搜索算法执行所需存储空间的大小。 这通常指算法需要存储的节点数量。 空间复杂度直接影响算法的可扩展性,尤其是在处理大型状态空间时。
- 例子: BFS 的空间复杂度是 O(b<sup>d</sup>),因为它需要存储所有深度小于等于 d 的节点。 DFS 的空间复杂度是 O(bd),因为它只需要存储从根节点到当前节点的路径上的节点。 迭代加深搜索 (IDDFS) 结合了 BFS 的完备性和 DFS 的空间效率,它的空间复杂度是 O(bd)。
4. 最优性 (Optimality):
最优性是指搜索策略是否保证能够找到最优解,即代价最小的解。 代价的定义取决于具体问题,例如路径长度、成本等。
- 例子: BFS 在使用一致代价的情况下能够找到最优解。 A* 算法在满足某些条件(启发式函数的可采纳性和一致性)下能够找到最优解。 DFS 和贪婪最佳优先搜索通常不能保证找到最优解。
搜索控制策略
1. 不可撤回的控制策略:
不可撤回的控制策略一旦做出选择,就不会回溯。 这意味着,一旦算法选择了一条路径,它就会沿着这条路径一直走到尽头,即使这条路径最终证明是错误的。 这种策略通常效率较低,因为可能会探索许多无用的路径。
- 例子: 深度优先搜索 (DFS) 在某种程度上可以看作是一种不可撤回的策略,因为它会沿着一条路径一直深入搜索,直到到达叶子节点或找到解。 一旦到达叶子节点,它才会回溯到之前的节点,但这个回溯是基于已经探索完一条路径的结果,而不是在路径探索过程中进行的。
2. 试探性控制策略:
试探性控制策略允许算法在搜索过程中回溯,并尝试不同的路径。 这种策略通常比不可撤回的控制策略效率更高,因为它可以避免探索无用的路径。 试探性控制策略又可以细分为回溯型和图搜索两种。
a) 回溯型 (Backtracking):
回溯型策略是一种试探性控制策略,它在探索一条路径时,如果发现这条路径无法到达目标状态,则回溯到之前的状态,并尝试另一条路径。 它通过维护一个状态栈来记录搜索过程中的状态,当发现当前状态无法继续搜索时,就弹出栈顶状态,并尝试其他分支。
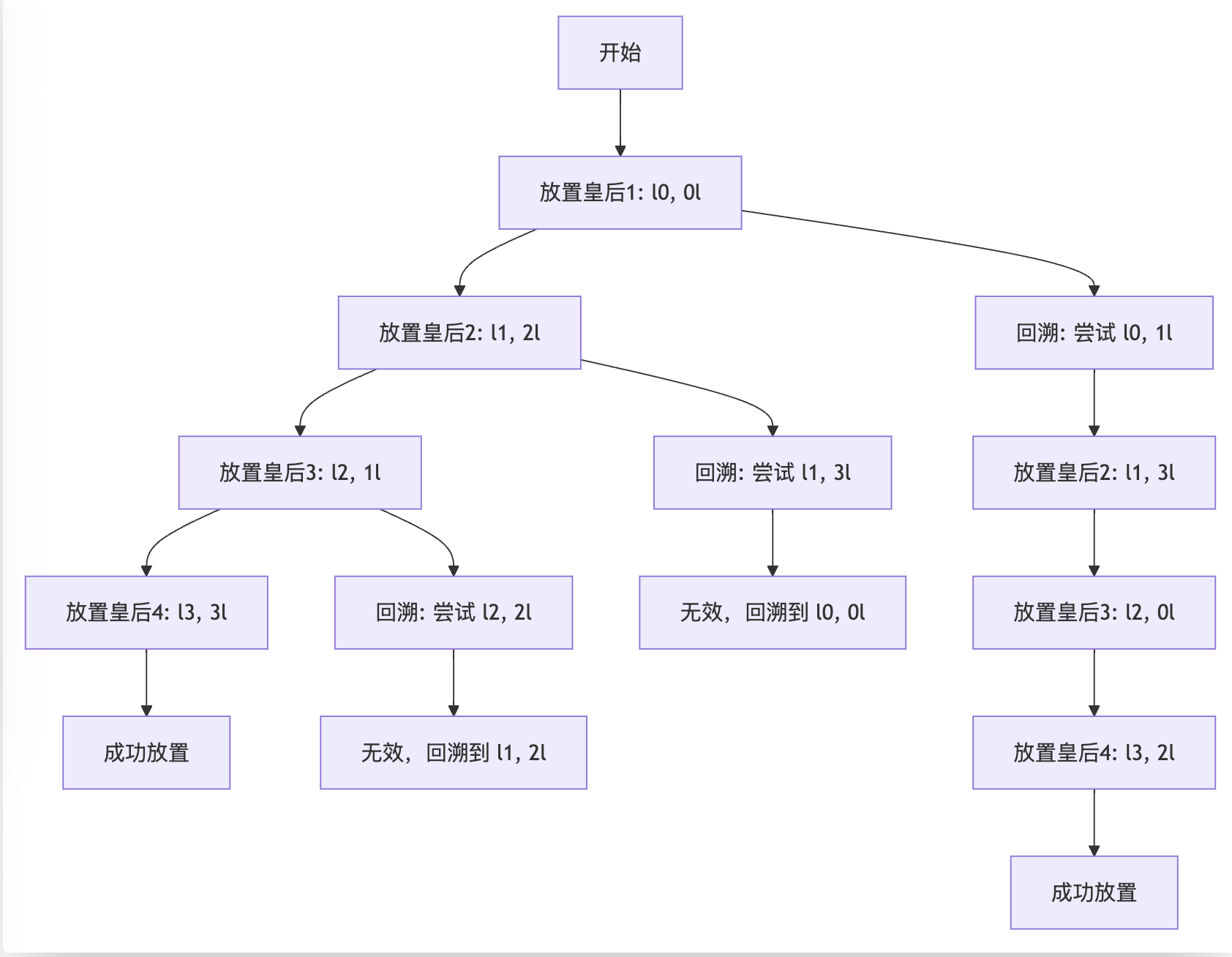
- 四皇后问题示例: 四皇后问题要求在 4×4 的棋盘上放置 4 个皇后,使得任何两个皇后都不能互相攻击。 回溯法可以用来解决这个问题。 算法从第一个皇后开始,依次尝试在每一列放置皇后。 如果发现当前的放置方案会导致冲突(两个皇后互相攻击),则回溯到前一个皇后,并尝试不同的位置。 如果所有皇后都成功放置,则找到一个解。
- 野人过河问题示例: 野人过河问题要求将三个野人和三个传教士用一条船渡过河,船每次只能载两个人,且任何时候河的两岸都不能让野人的数量超过传教士的数量(否则传教士会被吃掉)。 回溯法也可以用来解决这个问题。 算法从初始状态开始,尝试不同的渡河方案。 如果发现某个方案会导致野人数量超过传教士数量,则回溯到之前的状态,并尝试不同的方案。 如果所有野人和传教士都成功渡河,则找到一个解。
b) 图搜索 (Graph Search):
图搜索是一种试探性控制策略,它将搜索空间表示为一个图,其中节点代表状态,边代表状态之间的转换。 图搜索算法通过遍历图来寻找目标状态。 图搜索算法通常会使用一些数据结构(例如,队列或堆)来管理待探索的节点,并避免重复探索已经访问过的节点。
- 四皇后问题示例: 图搜索也可以应用于四皇后问题。 每个节点代表棋盘上皇后的一个放置方案,边代表从一个放置方案到另一个放置方案的转换。 图搜索算法可以遍历这个图,寻找满足条件的节点。
- 野人过河问题示例: 类似地,野人过河问题也可以用图搜索来解决。 每个节点代表野人和传教士在河两岸的分布情况,边代表不同的渡河方案。 图搜索算法可以遍历这个图,寻找能够将所有野人和传教士渡过河的路径。

3.4 启发式搜索
启发式搜索用于两种不同类型的问题:
前向推理
反向推理
前向推理一般用于状态空间的搜索。在前向推理中,推 理是从预选定义的初始状态出发向目标状态方向执行。
反向推理一般用于问题规约中。在反向推理中,推理是从给定的目标状态向初始状态执行。
(启发式搜索)如果在选择节点时能充分 利用与问题有关的特征信息,估计出节 点的重要性,就能在搜索时选择重要性 较高的节点,以便求得最优解。
用来评估节点重要性的函数 称为评估函数。
• 评估函数为:
f(x)=g(x)+h(x)
g(x):从初始节点S0 到节点x的实际代价(已经付出的代价);
h(x):从x到目标节点Sg 的最优路径的评估代价(将要付出的代价),它体现了问题的启发式信息,其形式要根据问题的特性确定, h(x) 称为启发式函数。
启发式方法把问题状态的描述转换成了对问题解决程度的描述,这一程度 用评估函数的值来表示。
引例:八数码问题S0和Sg
评估函数:f(x)=d(x)+w(x)
d(x)表示节点在x搜索树中的深度, w(x)表示节点x中不在目标状态中相应位置的数码个数,w(x)就包含了问题的
启发式信息。
• 一般来说某节点的w(x)越大,即“不在目标位”的数码个数越多,说明它 离目标节点越远。
对初始节点S0 ,由于d(S0 )=0,w(S0 )=5,因此f(S0 )=5。
最好优先搜索与深度优先算法的比较
**最好优先搜索(Best-First Search)和深度优先搜索(Depth-First Search)**是两种常用的搜索算法,它们在策略和实现上有显著的不同。
最好优先搜索
- 策略:最好优先搜索算法从最有希望的节点开始搜索,并生成其所有的子节点。它使用启发式函数来评估节点的优先级。
- 代价函数:该算法只关注当前节点到目标节点之间的代价,使用的代价函数为 $f(n) = h(n)$,其中 $h(n)$ 是从节点 $n$ 到目标节点的估计代价。这意味着它倾向于选择那些看起来最接近目标的节点进行扩展 [1][2]。
- 优先队列:实现时通常使用优先队列来管理待处理的节点,确保每次都选择估价最低的节点进行扩展。
深度优先搜索
- 策略:深度优先搜索算法则是沿着树的深度进行搜索,尽可能深入到每个分支,直到达到目标节点或没有更多的子节点为止。
- 代价函数:它只关注从初始节点 $S$ 到当前节点的实际代价,使用的代价函数为 $f(n) = g(n)$,其中 $g(n)$ 是从起始节点到节点 $n$ 的实际代价。这使得深度优先搜索在某些情况下可能会忽略更优的路径 [1][2]。
- 栈结构:通常使用栈(或递归)来实现,后进先出(LIFO)的特性使得它总是优先探索最新添加的节点。
总结
- 效率:最好优先搜索在找到目标节点时通常更高效,因为它利用启发式信息来指导搜索方向,而深度优先搜索可能会在某些情况下陷入无效的深度探索。
- 路径质量:最好优先搜索更有可能找到较短的路径,而深度优先搜索则可能找到较长的路径,尤其是在没有良好启发式信息的情况下。
➢ ➢ ➢ ➢
启发性信息和评估函数
Dijkstra算法
A算法
迭代加深A算法
3.4 与或图搜索
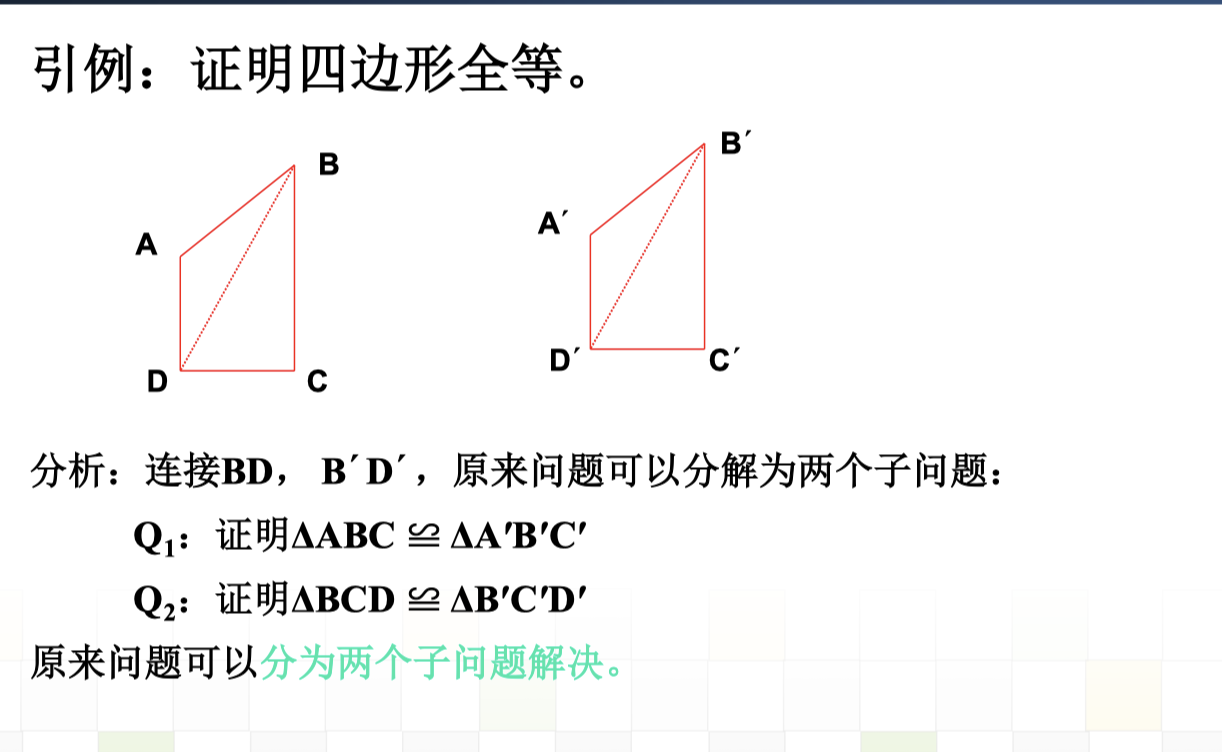

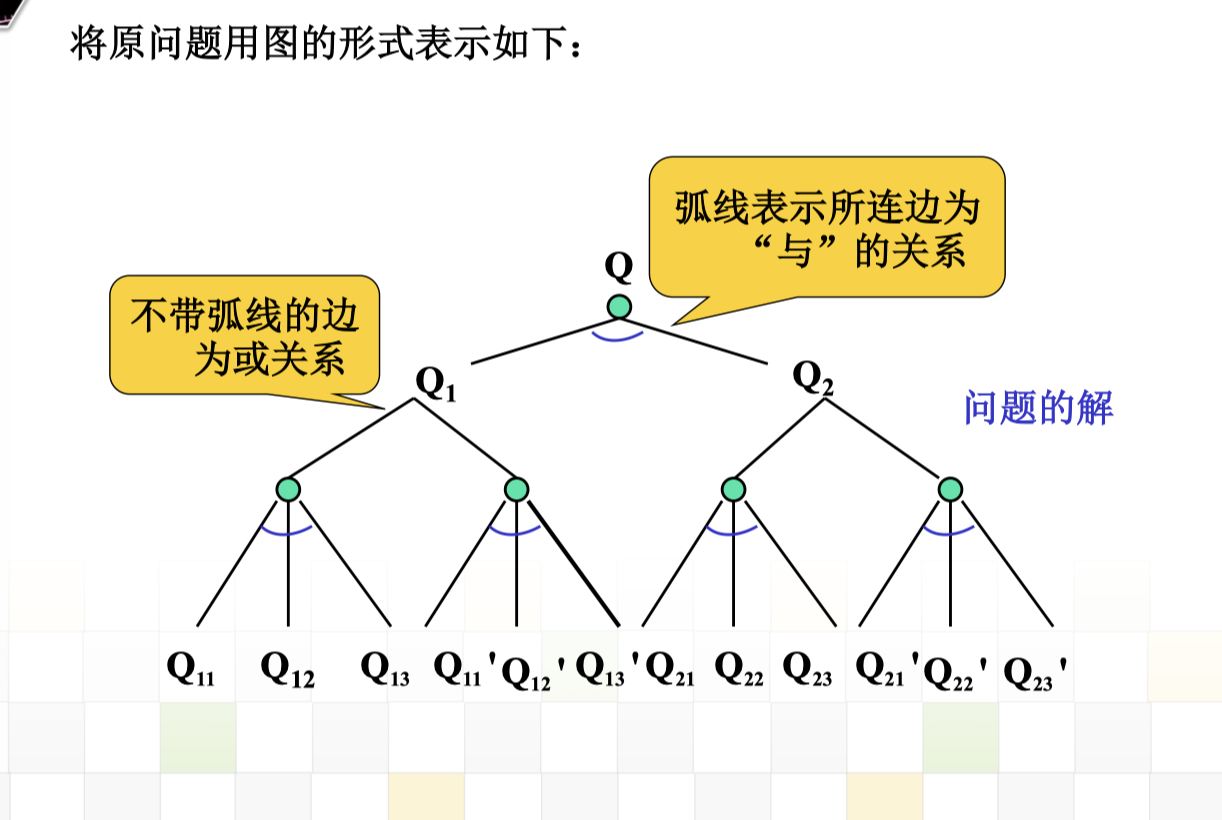
与或图的几个概念
直接可解的问题称为本原问题。
本原问题对应的节点称为终止节点。
无子节点的节点称为端节点。
子节点为与关系,则该节点为与节点。
子节点为或关系,则该节点为或节点。
- 可解性判别
怎样判断一个节点的可解性呢? 下面给出判别准则。 (1) 一个节点是可解, 则节点须满足下列条件之一:
① 终止节点是可解节点。
② 一个与节点可解, 当且仅当其子节点全都可解。
③ 一个或节点可解, 只要其子节点至少有一个可解。
(2) 一个节点是不可解, 则节点须满足下列条件之一:
① 非终止节点的端节点是不可解节点。
② 一个与节点不可解, 只要其子节点至少有一个不可解。
③ 一个或节点不可解, 当且仅当其子节点全都不可解。
- 搜索算法
与或树的树式搜索过程可概括为以下步骤:
步1 把初始节点Qo 放入OPEN表。
步2 移出OPEN表的第一个节点N放入CLOSED表, 并冠以序号n。
步3 若节点N可扩展, 则做下列工作:
步4 若N不可扩展, 则做下列工作:
(1)标记N为不可解节点, 然后由它的不可解反向推断其
先辈节点的可解性, 并对其中的不可解节点进行标记 。如果 初始节点So 也被标记为不可解节点, 则搜索失败, 退出。
(2)删去OPEN表中那些具有不可解先辈的节点 (因为其先 辈节点已不可解,故已无再考察这些节点的必要), 转步2。
点, g(x)=0。
3.4.3 启发式与或树搜索
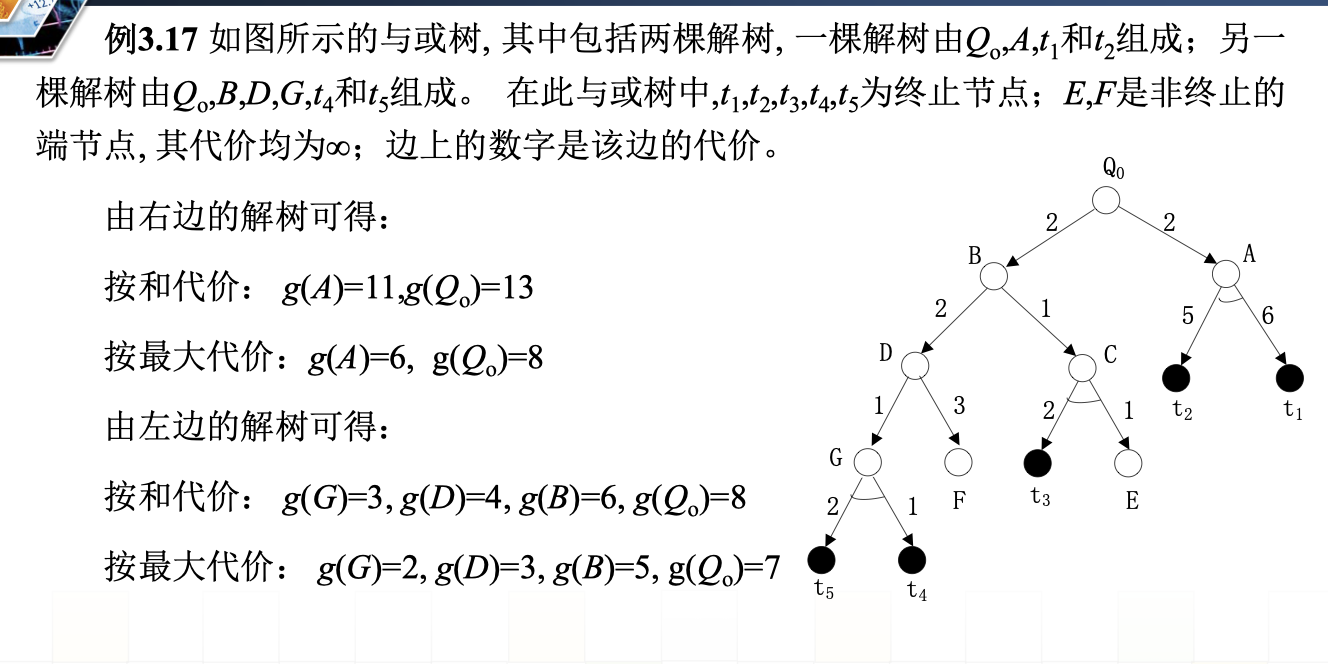
- 解树的代价
解树的代价就是树根的代价 。 树根的代价是 从树叶开始 自下而上逐层计算而求得的 。 而解树的根对应的是初始节点 Qo 。 这就是说,在与或树的搜索过程中,代价的计算方向与搜 索树的生长方向相反。这一点是与状态图不同的。具体来讲, 有下面的计算方法:
设g(x)表示节点x的代价,c(x,y)表示节点x到其子节点y的代 价 即边xy的代价), 则
(1) 若x是终止节点, g(x)=0。

Comments | NOTHING